Grafana Dashboard for Prometheus Monitoring
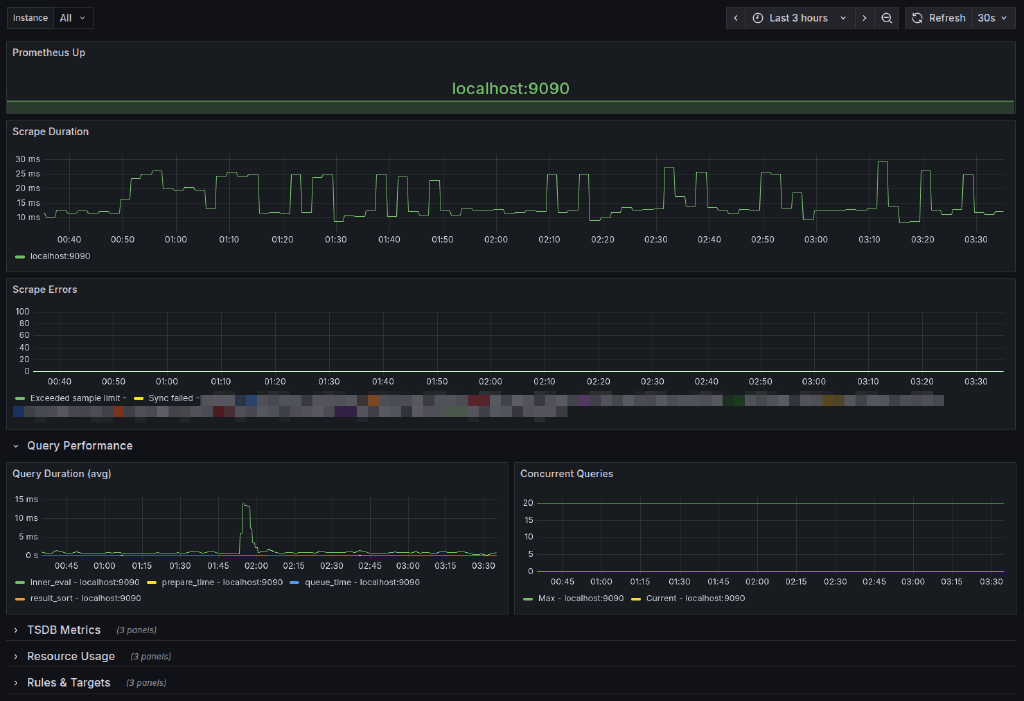
A comprehensive Grafana dashboard designed to monitor Prometheus itself, providing visibility into Prometheus performance, resource usage, and operational metrics.
Overview
This dashboard helps you monitor the health and performance of your Prometheus instance(s), including:
- Uptime Status: Track Prometheus availability with color-coded instance status
- Query Performance: Monitor query duration and concurrent queries
- Scrape Metrics: Track scrape duration and scrape errors
- TSDB Metrics: View time-series database head series, chunks, and health
- Resource Usage: Monitor memory consumption, CPU time, and goroutines
- Rule Evaluation: Track rule evaluation duration and failures
- Active Targets: Keep track of active scrape targets
Features
- Instance Filtering: Filter metrics by specific Prometheus instance or view all instances together
- Multi-Instance Support: Display status for multiple Prometheus instances with color-coded indicators
- Organized Layout: Collapsible sections for TSDB Metrics, Resource Usage, and Rules & Targets
- Real-time Updates: 30-second refresh interval
- 3-Hour Default Time Range: Configurable time window for historical data